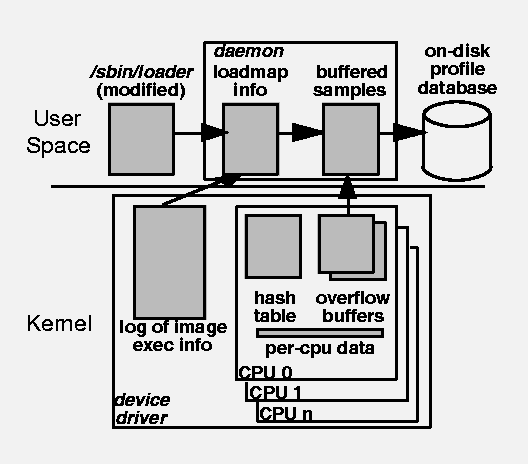
Figure 5: Data Collection System Overview
4. Data Collection System
The analysis tools described in the previous section rely on profiles gathered as the workload executes. To gather these profiles, the DIGITAL Continuous Profiling Infrastructure periodically samples the program counter (PC) on each processor, associates each sample with its corresponding executable image, and saves the samples on disk in compact profiles. The key to our system's ability to support high-frequency continuous profiling is its efficiency: it uses about 1--3% of the CPU, and modest amounts of memory and disk. This is the direct result of careful design.
Sampling relies on the Alpha processor's performance-counter hardware to count various events, such as cycles and cache misses, for all instructions executed on the processor. Each processor generates a high-priority interrupt after a specified number of events has occurred, allowing the interrupted instruction and other context to be captured. Over time, the system gathers more and more samples, which provide an accurate statistical picture of the total number of events associated with each instruction in every executable image run on the system. (There are a few blind spots in uninterruptible code; however, all other code is profiled, unlike systems that rely on the real-time clock interrupt or other existing system functions to obtain samples.) The accumulated samples can then be analyzed, as discussed in Section 6, to reveal useful performance metrics at various levels of abstraction, including execution counts and the average number of stall cycles for each instruction, as shown in Section 3.
The key to our system's ability to support high-frequency continuous profiling is its efficiency: it uses about 1-3% of the CPU, and modest amounts of memory and disk. This is the direct result of careful design. Figure 5 shows an overview of the data collection system. At an abstract level, the system consists of three interacting components: a kernel device driver that services performance-counter interrupts; a user-mode daemon process that extracts samples from the driver, associates them with executable images, and merges them into a nonvolatile profile database; and a modified system loader and other mechanisms for identifying executable images and where they are loaded by each running process. The rest of this section describes these pieces in more detail, beginning with the hardware performance counters.
Alpha processors[DEC95a] [DEC95b] provide a small set of hardware performance counters that can each be configured to count a specified event. The precise number of counters, set of supported events, and other interface details vary across Alpha processor implementations. However, all existing Alpha processors can count a wide range of interesting events, including processor clock cycles (CYCLES), instruction cache misses (IMISS), data cache misses (DMISS), and branch mispredictions (BRANCHMP).
When a performance counter overflows, it generates a high-priority interrupt that delivers the PC of the next instruction to be executed[SitW95] [DEC95a] and the identity of the overflowing counter. When the device driver handles this interrupt, it records the process identifier (PID) of the interrupted process, the PC delivered by the interrupt, and the event type that caused the interrupt.
Our system's default configuration monitors CYCLES and IMISS events. (We monitor CYCLES to obtain the information needed to estimate instruction frequency and cpi; see Section 6 for details. We also monitor IMISS because the IMISS samples are usually accurate, so they provide important additional information for understanding the causes of stalls; see the discussion in Section 4.1.2.) Monitoring CYCLES results in periodic samples of the program counter, showing the total time spent on each instruction. Monitoring IMISS events reveals the number of times each instruction misses in the instruction cache. Our system can also be configured to monitor other events (e.g., DMISS and BRANCHMP), giving more detailed information about the causes for dynamic stalls. Since only a limited number of events can be monitored simultaneously (2 on the 21064 and 3 on the 21164), our system also supports time-multiplexing among different events at a very fine grain. (SGI's Speedshop[Zag96] provides a similar multiplexing capability.)
Performance counters can be configured to overflow at different values; legal settings vary on different Alpha processors. When monitoring CYCLES on the Alpha 21064, interrupts can be generated every 64K events or every 4K events. On the 21164, each 16-bit performance counter register is writable, allowing any inter-interrupt period up to the maximum of 64K events to be chosen. To minimize any systematic correlation between the timing of the interrupts and the code being run, we randomize the length of the sampling period by writing a pseudo-random value[Car90] into the performance counter at the end of each interrupt. The default sampling period is distributed uniformly between 60K and 64K when monitoring CYCLES.
To accurately interpret samples, it is important to understand the PC delivered to the interrupt handler. On the 21164, a performance counter interrupt is delivered to the processor exactly six cycles after the counter overflows. When the interrupt is delivered, the handler is invoked with the PC of the oldest instruction that was in the issue queue at the time of interrupt delivery. The delayed delivery does not skew the distribution of cycle counter overflows; it just shifts the sampling period by six cycles. The number of cycle counter samples associated with each instruction is still statistically proportional to the total time spent by that instruction at the head of the issue queue. Since instructions stall only at the head of the issue queue on the 21064 and 21164, this accounts for all occurrences of stalls.
Events that incur more than six cycles of latency can mask the interrupt latency. For example, instruction-cache misses usually take long enough that the interrupt is delivered to the processor before the instruction that incurred the IMISS has issued. Thus, the sampled PC for an IMISS event is usually (though not always) correctly attributed to the instruction that caused the miss.
For other events, the six-cycle interrupt latency can cause significant problems. The samples associated with events caused by a given instruction can show up on instructions a few cycles later in the instruction stream, depending on the latency of the specific event type. Since a dynamically varying number of instructions, including branches, can occur during this interval, useful information may be lost. In general, samples for events other than CYCLES and IMISS are helpful in tracking down performance problems, but less useful for detailed analysis.
Performance-counter interrupts execute at the highest kernel priority level (SPLDEVRT), but are deferred while running non-interruptible PALcode[SitW95] or system code at the highest priority level. (This makes profiling the performance-counter interrupt handler difficult. We have implemented a "meta" method for obtaining samples within the interrupt handler itself, but space limitations preclude a more detailed discussion.) Events in PALcode and high-priority interrupt code are still counted, but samples for those events will be associated with the instruction that runs after the PALcode finishes or the interrupt level drops below SPLDEVRT.
For synchronous PAL calls, the samples attributed to the instruction following the call provide useful information about the time spent in the call. The primary asynchronous PAL call is ``deliver interrupt,'' which dispatches to a particular kernel entry point; the samples for ``deliver interrupt'' accumulate at that entry point. The other samples for high-priority asynchronous PAL calls and interrupts are both relatively infrequent and usually spread throughout the running workload, so they simply add a small amount of noise to the statistical sampling.
Our device driver efficiently handles interrupts generated by Alpha
performance counter overflows, and provides an ioctl interface
that allows user-mode programs to flush samples from kernel buffers to
user space.
The interrupt rate is high: approximately 5200 interrupts per second on each processor when monitoring CYCLES on an Alpha 21164 running at 333 MHz, and higher with simultaneous monitoring of additional events. This raises two problems. First, the interrupt handler has to be fast; for example, if the interrupt handler takes 1000 cycles, it will consume more than 1.5% of the CPU. Note that a cache miss all the way to memory costs on the order of 100 cycles; thus, we can afford to execute lots of instructions but not to take many cache misses. Second, the samples generate significant memory traffic. Simply storing the raw data (16-bit PID, 64-bit PC, and 2-bit EVENT) for each interrupt in a buffer would generate more than 52 KB per processor per second. This data will be copied to a user-level process for further processing and merging into on-disk profiles, imposing unacceptable overhead.
We could reduce these problems by resorting to lower-frequency event sampling, but that would increase the amount of time required to collect useful profiles. Instead, we engineered our data collection system to reduce the overhead associated with processing each sample. First, we reduce the number of samples that have to be copied to user space and processed by the daemon by counting, in the device driver, the number of times a particular sample has occurred recently. This typically reduces the data rate of sample data moving from the device driver to the user-level daemon by a factor of 20 or more. Second, we organize our data structures to minimize cache misses. Third, we allocate per-processor data structures to reduce both writes to shared cache lines and the synchronization required for correct operation on a multiprocessor. Fourth, we switch dynamically among specialized versions of the interrupt handler to reduce the time spent checking various flags and run-time constants. The rest of this section describes our optimizations in more detail.
Each processor maintains its own private set of data structures. A processor's data structures are primarily modified by the interrupt routine running on that processor. However, they can also be read and modified by the flush routines that copy data to user space. Synchronization details for these interactions are discussed in Section 4.2.3.
Each processor maintains a hash table that is used to aggregate samples by counting the number of times each (PID, PC, EVENT) triple has been seen. This reduces the amount of data that must be passed from the device driver to the user-level daemon by a factor of 20 or more for most workloads, resulting in less memory traffic and lower processing overhead per aggregated sample. The hash table is implemented with an array of fixed size buckets, where each bucket can store four entries (each entry consists of a PID, PC, and EVENT, plus a count).
A pair of overflow buffers stores entries evicted from the hash table. Two buffers are kept so entries can be appended to one while the other is copied to user space. When an overflow buffer is full, the driver notifies the daemon, which copies the buffer to user space.
The interrupt handler hashes the PID, PC, and EVENT to obtain a bucket index i; it then checks all entries at index i. If one matches the sample, its count is incremented. Otherwise one entry is evicted to an overflow buffer and is replaced by the new sample with a count of one. The evicted entry is chosen using a mod-4 counter that is incremented on each eviction. Each entry occupies 16 bytes; therefore, a bucket occupies one cache line (64 bytes) on an Alpha 21164, so we incur at most one data-cache miss to search the entire bucket.
The four-way associativity of the hash table helps to prevent thrashing of entries due to hashing collisions. In Section 5 we discuss experiments conducted to evaluate how much greater associativity might help.
A cache miss all the way out to memory costs on the order of 100 cycles. Indeed, it turns out that cache misses, for both instructions and data, are one of the dominant sources of overhead in the interrupt handler; we could execute many more instructions without a significant impact on overhead as long as they did not result in cache misses.
To reduce overhead, we designed our system to minimize the number of cache misses. In the common case of a hash table hit, the interrupt handler accesses one bucket of the hash table; various private per-processor state variables such as a pointer to the local hash table, the seed used for period randomization, etc; and global state variables such as the size of the hash table, the set of monitored events, and the sampling period.
On the 21164, the hash table search generates at most one cache miss. Additionally, we pack the private state variables and read-only copies of the global variables into a 64 byte per-processor data structure, so at most one cache miss is needed for them. By making copies of all shared state, we also avoid interprocessor cache line thrashing and invalidations.
In the uncommon case of a hash table miss, we evict an old entry from the hash table. This eviction accesses one extra cache line for the empty overflow buffer entry into which the evicted entry is written. Some per-processor and global variables are also accessed, but these are all packed into the 64 byte per-processor structure described above. Therefore these accesses do not generate any more cache misses.
Synchronization is eliminated between interrupt handlers on different processors in a multiprocessor, and minimized between the handlers and other driver routines. Synchronization operations (in particular, memory barriers[SitW95]) are expensive, costing on the order of 100 cycles, so even a small number of them in the interrupt handler would result in unacceptable overhead. The data structures used by the driver and the techniques used to synchronize access to them were designed to eliminate all expensive synchronization operations from the interrupt handler.
We use a separate hash table and pair of overflow buffers per processor, so handlers running on different processors never need to synchronize with each other. Synchronization is only required between a handler and the routines that copy the contents of the hash table and overflow buffers used by that handler to user space. Each processor's hash table is protected by a flag that can be set only on that processor. Before a flush routine copies the hash table for a processor, it performs an inter-processor interrupt (IPI) to that processor to set the flag indicating that the hash table is being flushed. The IPI handler raises its priority level to ensure that it executes atomically with respect to the performance-counter interrupts. If the hash table is being flushed, the performance counter interrupt handler writes the sample directly into the overflow buffer. Use of the overflow buffers is synchronized similarly.
Although IPIs are expensive, they allow us to remove all memory barriers from the interrupt handler, in exchange for increasing the cost of the flush routines. Since the interrupt handler runs much more frequently than the flush routines, this is a good tradeoff.
A user-mode daemon extracts samples from the driver and associates them with their corresponding images. Users may also request separate, per-process profiles for specified images. The data for each image is periodically merged into compact profiles stored as separate files on disk.
The main daemon loop waits until the driver signals a full overflow buffer; it then copies the buffer to user space and processes each entry. The daemon maintains image maps for each active process; it uses the PID and the PC of the entry to find the image loaded at that PC in that process. The PC is converted to an image offset, and the result is merged into a hash table associated with the relevant image and EVENT. The daemon obtains its information about image mappings from a variety of sources, as described in the following section.
Periodically, the daemon extracts all samples from the driver data structures, updates disk-based profiles and discards data structures associated with terminated processes. The time intervals associated with periodic processing are user-specified parameters; by default, the daemon drains the driver every 5 minutes, and in-memory profile data is merged to disk every 10 minutes. This simple timeout-based approach can cause undesirable bursts of intense daemon activity; the next version of our system will avoid this by updating disk profiles incrementally. A complete flush can also be initiated by a user-level command.
We use several sources of information to determine where images are
loaded into each process. First, a modified version of the dynamic system
loader (/sbin/loader) notifies our
system's daemon whenever an image is loaded into a process.
The notification contains the PID, a unique identifier for each
loaded image, the address at which it was loaded, and its filesystem
pathname. This mechanism captures all dynamically loaded images.
Second, the kernel exec path invokes a chain of recognizer
routines to determine how to load an image. We register a
special routine at the head of this chain that captures information
about all static images. The recognizer stores this data in a kernel
buffer that is flushed by the daemon every few seconds.
Finally, to obtain image maps for processes already active when the daemon starts, on start-up the daemon scans all active processes and their mapped regions using Mach-based system calls available in DIGITAL Unix.
Together, these mechanisms are able to successfully classify virtually all samples collected by the driver. Any remaining unknown samples are aggregated into a special profile. In our experience, the number of unknown samples is considerably smaller than 1%; a typical fraction from a week-long run is 0.05%.
The daemon stores samples in an on-disk profile database. This database resides in a user-specified directory, and may be shared by multiple machines over a network. Samples are organized into non-overlapping epochs, each of which contains all samples collected during a given time interval. A new epoch can be initiated by a user-level command. Each epoch occupies a separate sub-directory of the database. A separate file is used to store the profile for a given image and EVENT combination.
The profile files are written in a compact binary format. Since significant fractions of most executable images consist of symbol tables and instructions that are never executed, profiles are typically smaller than their associated executables by an order of magnitude, even after days of continuous profiling. Although disk space usage has not been a problem, we have also designed an improved format that can compress existing profiles by approximately a factor of three.
Beginning of paper
Abstract
1. Introduction
2. Related Work
3. Data Analysis Examples
4. Data Collection System
5. Profiling Performance
6. Data Analysis Overview
7. Future Directions
8. Conclusions
Acknowledgements
References