The general goal of the APIs presented in this document is to separate core recommendation functionality from application-dependent features such as choice of platform, database, communication mechanism, etc. Implementing the "glue" code to connect these APIs into a complete application is straightforward.
The APIs are written in C++, but avoid advanced C++ features (e.g., no multiple inheritance, templates, or exceptions). Bindings for other languages (e.g., Java, C) would not be difficult to design.
This document describes everything needed for pure vote-based predictions of person-item and person-person affinity (the latter to be used for choosing reviews of potential interest to a person). The appendix describes an enhancement called categories, which allow the use of demographic information and item categorization information in predictions. We have little experience with categories.
The technology is available for licensing; see Appendix B: Technology Availability.
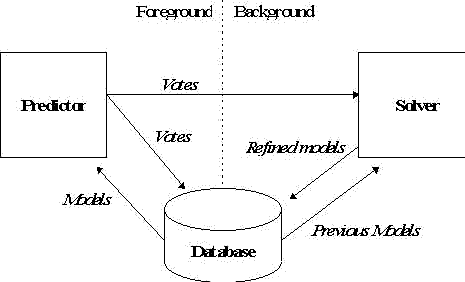
The prediction component, or predictor for short, is inherently interactive. The analysis component, or solver for short, does not need to have low-latency communication with the prediction function or the user interface. In a typical internet application, the predictor runs as an application gateway, accessed via an interface such as CGI, NSAPI, or ISAPI, while the solver runs as a stand-alone process, perhaps on a different server computer. In a retail kiosk application, the predictor runs in the kiosk computer while the solver runs at a central data center; periodic dial-up communication is used to send votes to the solver and updated models to the kiosks. Finally, in a CD-ROM application, the predictor runs on a personal computer, using pre-computed models stored on the CD-ROM. Votes are stored on the local hard drive, and optionally sent to a central data center via dial-up communication and/or the Internet. Here is a diagram showing the overall data flow:
There are a few other terms with special meanings in this document:
Person: someone who votes for items and asks for recommendations.
Item: something that can be voted on.
Vote: actual or predicted assessment of an item by a person, consisting of a score and a weight.
Score: a numeric value between 0.0 and 1.0, where higher numbers mean more positive assessments.
Weight: a nonnegative floating-point value. On input to Each to Each, weights have a linear interpretation (e.g., .5 means half as confident as 1.0), but the particular scale (e.g., 0.0 to 1.0 or 0.0 to 10.0) doesn't matter. On output from Each to Each, weights are approximate and ordered but not linear and will be between 0.0 and 1.0. Determining appropriate thresholds upon which to base recommendations typically requires a bit of application-dependent tuning.
Model: a block of data (currently 128 bytes in length) computed by the solver for each person and for each item. The predictor functions use the model in fast algorithms for predicting votes and correlations.